Exposés 23 24
GraphQL (par Tom)
Alternative au APIs REST et approche moderne de déliverance des données.
Kesako ?
GraphQL est un langage de requête pour votre API et un environnement d'exécution de requêtes côté serveur pour exécuter ces requêtes en utilisant les données existantes. GraphQL décrit les données de l'API et fourni un moyen d'accès à ces données. Il suffit de piocher ce dont vous avez besoin.
Pourquoi GraphQL ?
-
Demander ce dont vous avez besoin : GraphQL permet aux clients de demander des données exactement comme ils en ont besoin. GraphQL est une alternative aux API REST.
-
Un seul point d'entrée : GraphQL fournit un seul point d'entrée pour exécuter des requêtes. Cela signifie que vous n'avez pas besoin de gérer plusieurs points d'entrée pour différentes versions de votre API.
-
Documentation automatique : GraphQL fournit une documentation automatique pour votre API. Cela signifie que vous n'avez pas besoin de maintenir une documentation séparée pour votre API.
-
Évolution de l'API : GraphQL permet d'évoluer l'API sans casser les clients existants. Cela signifie que vous pouvez ajouter de nouveaux champs à votre API sans casser les clients existants.
-
Outils de développement : GraphQL fournit des outils de développement puissants pour les développeurs. Cela signifie que vous pouvez, par exemple, utiliser des outils tels que GraphiQL pour tester vos requêtes GraphQL.
Pourquoi ne pas l'utiliser ?
- Cache : GraphQL a du mal à cacher ses données car contrairement aux API REST, les méthodes de caching ne sont pas définis par les CDNs, Proxies, Serveurs Web, et navigateurs.
- Coût de l'infrastructure : GraphQL nécessite plus de ressources pour exécuter des requêtes que les API REST.
- Client Integration Contrairement aux API REST, GraphQL nécessite un client spécialisé pour exécuter des requêtes. Cela signifie que vous devez utiliser un client GraphQL pour exécuter des requêtes GraphQL là où en REST, on utilise des outils simples comme cURL, intégrés dans la plupart des cas par défaut.
Comment ça marche ?
GraphQL est composé de 5 parties principales :
-
Queries (requêtes) : Les requêtes GraphQL sont utilisées pour demander des données spécifiques au serveur. Elles permettent aux clients de spécifier exactement quelles données ils ont besoin, et le serveur renvoie uniquement ces données.
-
Mutations (mutations) : Les mutations sont utilisées pour modifier les données du serveur. Contrairement aux requêtes, qui sont utilisées pour la lecture de données, les mutations permettent d'effectuer des opérations telles que la création, la mise à jour ou la suppression de données.
-
Types (types) : GraphQL définit un système de types pour décrire la structure des données disponibles. Les types sont utilisés pour spécifier quels champs peuvent être demandés sur un objet et quels types de données ils contiennent.
-
Schemas (schémas) : Un schéma GraphQL est une description de tous les types de données disponibles dans l'API, ainsi que des relations entre ces types. Il définit quels types de requêtes et de mutations peuvent être exécutés.
-
Resolvers (résolveurs) : Les résolveurs sont des fonctions qui définissent comment les données doivent être récupérées ou modifiées pour chaque champ d'un type dans le schéma. Chaque champ d'un type peut avoir son propre résolveur, ce qui permet une grande flexibilité dans la façon dont les données sont obtenues ou manipulées.

Exemple
Voici un exemple de requête GraphQL :
Experimenter
Dirigez-vous vers l'API GraphQL d'Atlassian
How Google/Apple Pay work (Julian)
Fonctionnement de l'Apple Pay
Apple Pay est système existant depuis 2013, permettant de pouvoir utiliser des cartes à l'aide de son téléphone, notamment des cartes bancaires. Cela fonctionne en utilisant le concept de tokenization. Dans un premier temps, lorsque vous allez rentrer vos informations bancaire dans votre device Apple, dans ces informations ce qui va nous intéresser c'est le PAN (numéro à 16 chiffres ou 19 suivant la carte, qui est au recto de votre carte bancaire). Après avoir saisi ces informations, le PAN va être enregistré sur un serveur sécurisé de Apple. Ensuite ce PAN va être vérifier par la banque puis à l'aide du TSP, un token va être ressorti. Ce token va être renvoyer au device Apple et va être stocké dans un élément sécurisé du device. Cet ensemble (élément sécurisé + token) s'appelle DAN.
Après avoir enregistrer votre carte, le paiement fonctionne à l'aide du système NFC du device. Lorsque vous approcher votre téléphone du TPE, à l'aide du NFC, le DAN va être envoyé au TPE, puis le TPE va communiquer avec la banque pour communiquer le DAN. Après vérification du token par la banque et par le moyen de paiement (visa, mastercard...), il va y avoir détokenisation à l'aide de TSP, puis le paiement s'effectuera avec les infos détokenisées.
Fonctionnement Google Pay
Google Pay, ou plutôt google wallet, existe depuis 2014. Anciennement android Pay, le fonctionnement de Google Pay est pratiquement le même que celui d'Apple Pay. Il y a quelques différences entre les 2 systèmes. Premièrement, le token généré à partir des informations bancaires, sur android, n'est pas stocké dans un élément sécurisé comme pour un device Apple. Le token va être stocké directement dans l'application Google Wallet. Deuxièmement, ce même token va être stocké sur un serveur de Google à la différence de Apple qui eux ne stockent pas cette information sur leur serveur.
Pour le paiement, le fonctionnement est similaire à celui d'Apple, à la différence qu'ils utilisent un système de HCE, (Host Card Emulation) avec le token récupérer du serveur ou de l'app.
Comment fonctionne Git ? (Hugo)
Tout d'abord, notre code réside non pas dans 2, mais 4 endroits différents :
| Endroit | Description |
|---|---|
| Espace de travail | Dossier courant de notre projet |
| Aire de Staging | Endroit temporaire où les changements de nos fichiers sont enregistrés |
| Dépôt local | Dépôt de nos changements validés uniquement présent sur notre ordinateur |
| Dépôt distant | Serveur (comme GitHub) pour partager et sauvegarder notre code |
Déroulé
La plupart des commandes git déplacent notre code entre ces 4 endroits:
sequenceDiagram
participant A as Espace de travail
participant B as Aire de staging
participant C as Dépôt local
participant D as Dépôt distant
D->>C: git clone
C->>A: git checkout
A->>B: git add
B->>C: git commit
C->>D: git push
D->>A: git pull-
git clone clone un répertoire distant en local, nous permettant de modifier ses fichiers dans notre espace de travail
-
git checkout bascule sur une autre branche ou restaure un espace de travail
-
git add ajoute le contenu des fichiers modifiés dans l'aire de staging en attendant leur validation
-
git commit enregistre les changements de l'aire de staging dans le dépôt local
-
git push envoie les changements locaux sur le dépôt distant
-
git pull récupère les changements du dépôt distant
La commande git pull est en réalité l'association de deux commandes : git fetch et git merge
flowchart LR
id1[(Dépôt distant)]-- git pull-->id2(Espace de travail)
id1[(Dépôt distant)]-- git fetch -->id3[(Dépôt local)]
id3[(Dépôt local)]-- git merge -->id2(Espace de travail)-
git fetch récupère les dernières mises à jour depuis le dépôt distant
-
git merge applique ces mises à jour au dépôt local
Git branching
L'intérêt de git réside dans son système de branche : un même dépôt peut contenir plusieurs versions d'un même code, cahcune résidant dans sa propre branche.
Les commandes git checkout (voir ci-dessus) et git switch permettent de naviguer entre ces branches.
flowchart LR
commit4-->commit1A-->commit2A~~~id2{{Branch A}}
commit1-->commit2-->commit3-->commit4-->commit5-->commit6~~~id1{{Main branch}}
commit2A-- git switch -->commit6
commit6-->commit2APratiques
On rencontre courramment différents noms de branches, chacun correspondant à un environnement précis :
- main ou master : production
- develop : développement
- feature : fonctionnalité qui sera fusionnée sur develop, puis sur main/master
- hotfix : qui vise à corriger un souci sur la main/master
- etc...
Conflits
Imaginons un cas dans lequel j'ai créé une branche depuis la develop, mais que celle-ci a évolué entretemps :
flowchart LR
commit4-->commit1A-->commit2A~~~id2{{feature/ft-mafeature}}
commit1-->commit2-->commit3-->commit4-->commit5-->commit6~~~id1{{develop}}Pour fusionner ma branche et la redescendre dans develop, je vais devoir intégrer son historique dans ma branche avec un rebase ou un merge de develop dans ma branche, ce qui me donnera l'historique local suivant au niveau de ma feature :
flowchart LR
commit4-->commit5-->commit6-->commit1A-->commit2A~~~id2{{feature/ft-mafeature}}Je peux ensuite la fusionner dans develop, ce qui à terme donnera
flowchart LR
commit4-->commit5-->commit6-->commit1A-->commit2A~~~id2{{develop}}Définition générale des propriétés ACID (Nidal)
Les propriétés ACID sont un ensemble de propriétés qui garantissent que les transactions sont fiables. Cela cignifie Atomicité, Cohérence, Isolation et Durabilité.
Atomicité (Atomicity)
Définition
L'atomicité signifie que les transactions sont traitées comme une seule unité. Cela signifie que toutes les opérations d'une transaction sont effectuées ou aucune d'entre elles ne l'est.
Exemple
- Exemple 1: Transfert d'argent entre deux comptes bancaires.
- Opérations:
- Débiter le compte A.
- Créditer le compte B.
- Atomicité: Si l'une des opérations échoue, les deux opérations sont annulées.
Remarques
- L'Atomicité est souvent implémentée en utilisant des logs.
Cohérence (Consistency)
Définition
La cohérence garantit que les données sont toujours valides avant et après une transaction. Elles doivent respecter toutes les contraintes, les règles et les relations. Si une transaction viole l'intégrité des données, elle est annulée.
Exemple
- Exemple 1: Transfert d'argent entre deux comptes bancaires.
- Contrainte: Le solde du compte ne peut pas être négatif.
- Cohérence: Si le solde du compte A est de 100€, et que l'on essaie de transférer 150€, la transaction est annulée.
Remarques
- La Cohérence est souvent implémentée en utilisant des contraintes, des règles et des relations.
- Par exemple, les clés étrangères dans une base de données relationnelle, ou les contraintes de vérification sur les champs (taille Varchar, etc...).
Isolation
Définition
L'isolation garantit que les transactions s'exécutent indépendamment les unes des autres. Cela signifie que les transactions ne peuvent pas interférer les unes avec les autres.
- Le plus haut niveau d'isolation est souvent difficile à atteindre en raison des performances. Il consiste à ne jamais permettre à deux transactions de se chevaucher. C'est ce qu'on appelle l'isolation de niveau serializable.
- Il existe plusieurs niveaux d'isolation, tels que read committed, repeatable read et serializable.
- Chaque niveau d'isolation a ses propres problèmes potentiels, tels que les dirty reads, les non-repeatable reads et les phantom reads.
Dirty Read
Un dirty read se produit lorsqu'une transaction lit des données qui ont été modifiées par une autre transaction, mais qui n'ont pas encore été validées.
Exemple de cas d'utilisation
La transaction A modifie une ligne où age = 30 pour le transformer à age = 40, mais n'a pas encore validé la transaction (par exemple, elle doit rollback).
La transaction B lit la ligne modifiée par la transaction A (elle reçoit age = 40.
La transaction A rollback, et la ligne est restaurée à son état initial (age = 30) MAIS la transaction B a déjà lu la ligne avec le résultat modifié (age = 40).
Non-repeatable Read
Un non-repeatable read se produit lorsqu'une transaction lit des données qui ont été modifiées par une autre transaction, puis relit ces données et obtient un résultat différent.
Exemple de cas d'utilisation
La transaction A lit une ligne où age = 30.
La transaction B modifie la ligne lue par la transaction A et age = 25.
La transaction A relit la ligne et obtient un résultat différent, ce qui peut causer une erreur.
Phantom Read
Un phantom read se produit lorsqu'une transaction lit un ensemble de lignes qui satisfont une condition, puis une autre transaction insère une nouvelle ligne qui satisfait la même condition, et la première transaction relit les données et obtient un résultat différent.
Exemple de cas d'utilisation
La transaction A lit toutes les lignes où age > 18.
La transaction B insère une nouvelle ligne où age = 20.
La transaction A relit toutes les lignes où age > 18 et obtient un résultat différent.
Exemple
- Exemple 1: Transfert d'argent entre deux comptes bancaires.
- Opérations:
- Débiter le compte A.
- Créditer le compte B.
- Isolation: Si deux transactions essaient de débiter le compte A en même temps, l'une des transactions doit attendre que l'autre soit terminée.
Remarques
- L'Isolation est souvent une question de performances. Plus le niveau d'isolation est élevé, plus les performances sont faibles. C'est pourquoi il est important de choisir le bon niveau d'isolation en fonction des besoins.
| Niveau d'isolation | Dirty Read | Non-repeatable Read | Phantom Read |
|---|---|---|---|
| Serializable | Impossible | Impossible | Impossible |
| Repeatable Read | Impossible | Impossible | Possible |
| Read Commited | Impossible | Possible | Possible |
Durabilité (Durability)
Définition
La durabilité garantit que les données d'une transaction sont enregistrées de manière permanente. Cela signifie que les données ne seront pas perdues, même en cas de panne du système. Dans les BDDs distribuées, cela signifie que les données sont répliquées sur plusieurs nœuds.
Exemple
- Exemple 1: Transfert d'argent entre deux comptes bancaires.
- Durabilité: Si la transaction est confirmée, les données sont enregistrées de manière permanente, même en cas de panne du système. Les données ne seront pas perdues, même si un nœud tombe en panne.
Remarques
- La Durabilité est souvent implémentée en utilisant des logs de type WAL (Write-ahead logging).
- Les logs de type WAL sont utilisés pour enregistrer les opérations avant de les exécuter. Cela garantit que les données sont enregistrées de manière permanente avant d'être exécutées.
Conclusion
- Les propriétés ACID sont essent,ielles pour garantir que les transactions sont fiables.
- Chaque propriété a un rôle important à jouer pour garantir la fiabilité des transactions.
- Il est important de comprendre les propriétés ACID pour concevoir des systèmes fiables et robustes.
- Les propriétés ACID sont souvent implémentées en utilisant des logs, des contraintes et des règles.
- Il est important de choisir le bon niveau d'isolation en fonction des besoins pour garantir des performances optimales.
Références
Chose DataBase (Romain)
Avant de changer de base de données
vérifiez si la base actuelle est réellement insuffisante. il faut examinez la documentation pour identifier des ajustements possibles qui pourraient résoudre les problèmes actuels.
Migrer une base de données
Migrer une base de données de production est risquée et gourmande en energie. Assurez-vous d'avoir épuisé toutes les améliorations possibles avec le système actuel avant de migrer.
Le Choix de la base de données
il faut prendres des bases de données éprouvées et stables. il faut aussi faire attention aux nouvelles technologies non testées.
Lire la Documentation
Pour comprendre les limitations d'une nouvelle base de données, étudiez soigneusement sa documentation, en particulier les sections sur les limites et les FAQ.
Faire de vrais tests
il faut faire des environnements de test réaliste en utilisant de vrais données et modèles d'accès pour voir quelle BDD est repondras au mieux a notre besion.
La migration
Aux moment de migrer il faudras le faire service par service et tester tout du long. cela pour verifier que la nouvelle BDD seras meilleur que l'ancienne
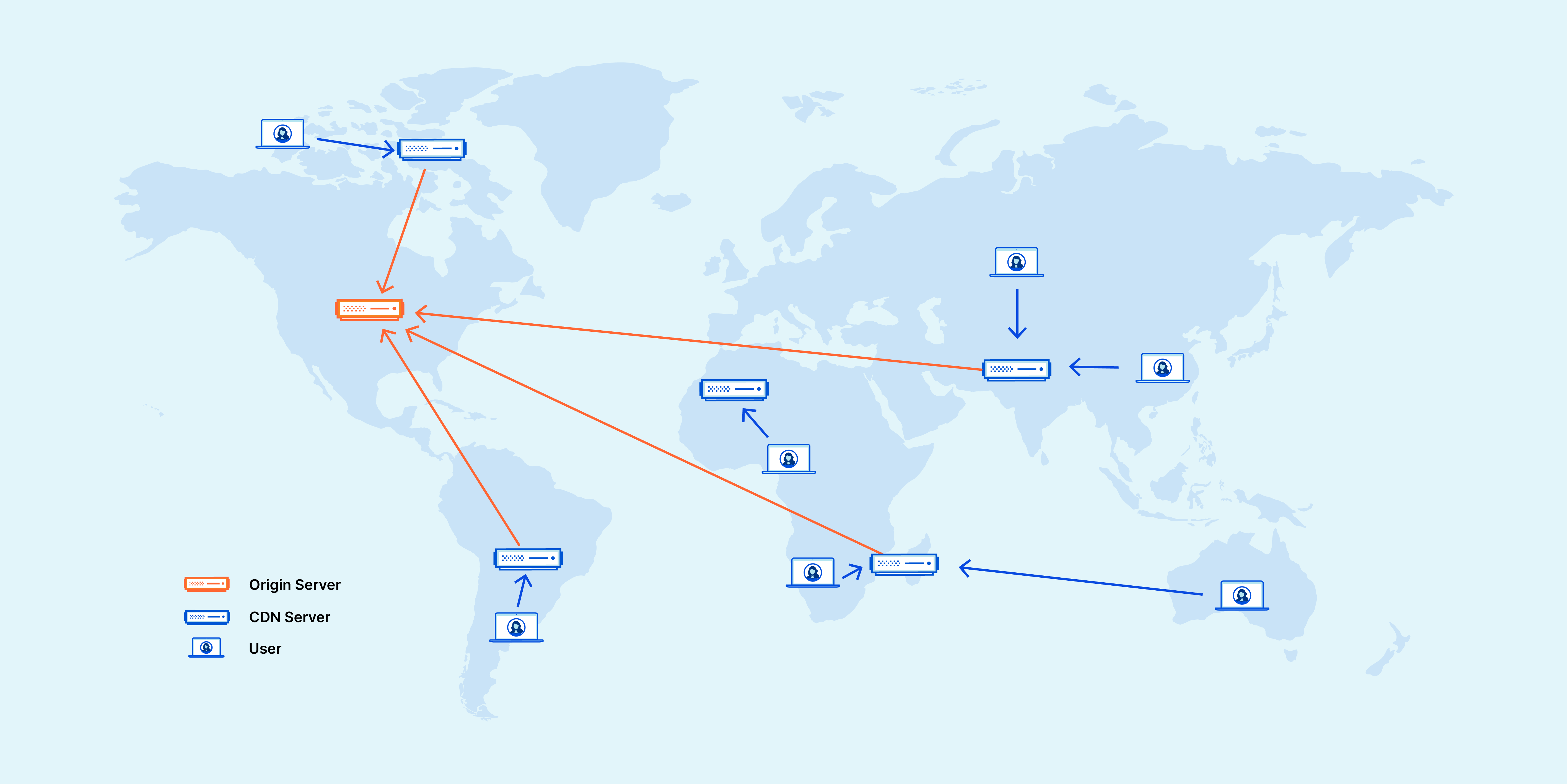
Les CDNs (Lucas)
JWT (JsonWebToken) (Thomas)
Qu'est qu'un JWT ?
Une methode qui permet de transmettre des informations entre plusieurs parties sous formes d'objet JSON
Structure du JWT
- Header
- Payload
- Signature
Tous ces champs sont en base64 et separé par des points
Structure du Header
- Type de token (en l'ocuurence JWT)
- Algorithme utilisé (SHA256, RSA, HMAC, ...)
Structure du Payload
- Tout les claims dont nous avons besoin (En general, notre user et quelques données necessaires)(Trois types de claim : Public, Private et Registered)
Structure de la Signature
- 2 types de signature : Symétrique et Asymétrique
Signature symétrique : Une clé privée est connu et partagé entre l'émetteur et le receveur, l'émetteur signe avec cette clé et le receveur valide avec cette meme clé. (HMAC, HS256). La signature symétrique est rapide et simple mais induit le partage de la clé privée
Signature asymétrique : Une clé privé est détenu par l'émetteur seulement avec laquelle il signe. Une clé publique est envoyé au receveur avec le token signé et le receveur valide la jwt avec la clé publique. La signature asymétrique evite le partage de la clé privée mais est plus longue en contrepartie
Utilisation des JWT
- Authentification
- Autorisation
- Echange d'informations
Exemple d'utilisation d'un JWT
- Le user se log
- Le serveur valide le login puis crée un token signé avec les details du user qu'il renvoie à celui-ci
- Le user l'utilise pour acceder au diverses ressources en le mettant dans le HTTP Header
Cas d'utilisation
- OAuth2
- OpenID
Cas où le JWT n'est pas recommandé
- Partage de données sensibles
- Gerer les sessions utilisateurs(car un JWT est stateless donc revoquer un acces peu etre compliqué)
Vulnerabilités du JWT
- Token hijacking pour imiter un utilisateur
- Cryptographic weakness si l'algo de hash est faible. Un brute force pourrait crack la signature du token
Pour réduire les risques
- Utiliser des temps d'expiration rapide si possible
- Utiliser une signature forte
- Stocker les tokens et invalidez les tokens qui ont fuité
Avantages
- Pas d'enregistrement nécessaires côté serveur
- Indépendant
Inconvenient
- Vulnerable au vol car peut donner un acces complet au ressources
- Performance dégradé si le payload est trop volumineux
Résumé
- Les JWTs permettent l'authentification, l'autorisation et l'échange d'informations